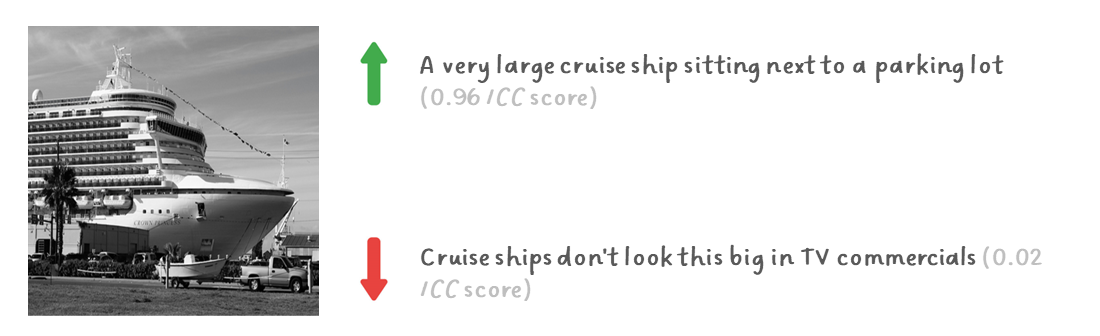




Images from COCO dataset with high ICC-scored caption and low ICC-scored caption. Even in the curated COCO dataset, ICC still manages to detect low-quality captions.
Abstract
Web-scale training on paired text-image data is becoming increasingly central to multimodal learning, but is challenged by the highly noisy nature of datasets in the wild. Standard data filtering approaches succeed in removing mismatched text-image pairs, but permit semantically related but highly abstract or subjective text. These approaches lack the fine-grained ability to isolate the \emph{most concrete} samples that provide the strongest signal for learning in a noisy dataset. In this work, we propose a new metric, Image Caption Concreteness, that evaluates caption text without an image reference to measure its concreteness and relevancy for use in multimodal learning. Our approach leverages strong foundation models for measuring visual-semantic information loss in multimodal representations. We demonstrate that this strongly correlates with human evaluation of concreteness in both single-word and sentence-level texts. Moreover, we show that curation using ICC complements existing approaches: It succeeds in selecting the highest quality samples from multimodal web-scale datasets to allow for efficient training in resource-constrained settings.
Usage
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch
tokenizer = AutoTokenizer.from_pretrained("moranyanuka/icc")
model = AutoModelForSequenceClassification.from_pretrained("moranyanuka/icc").to("cuda")
captions = ["a great method of quantifying concreteness", "a man with a white shirt"]
text_ids = tokenizer(captions, padding=True, return_tensors="pt", truncation=True).to("cuda")
with torch.inference_mode():
icc_scores = model(**text_ids)["logits"]
# tensor([[0.0339], [1.0068]])
Pipeline
Our pipeline is composed of two components: a Visual-Bottleneck Autoencoder (VBA) and a Semantic-Bottleneck Autoencoder (SBA). We distill their optimal combination to a small language model to generate the ICC scores.
We use an image as the visual bottleneck of the VBA and CLIP's text embeddings as the visual-semantic bottleneck of the SBA. Captions which are highly visual are likely to be reconstructed well by these pipelines, while abstract or subjective captions will likely fail to reconstruct.
Qualitative Results
Captioning results obtained by training over the extremenly noisy LAION-400M dataset, with different filtering methods.

Captioning models trained over ICC generate more concrete and accurate captions, even when training on the highly noisy LAION-400M.
Quantitative Results

We test the trained models on highly visual benchmarks, showing quantitatively that our models generate more concrete and accurate captions.
BibTeX
@misc{yanuka2024icc,
title={ICC: Quantifying Image Caption Concreteness for Multimodal Dataset Curation},
author={Moran Yanuka and Morris Alper and Hadar Averbuch-Elor and Raja Giryes},
year={2024},
eprint={2403.01306},
archivePrefix={arXiv},
primaryClass={cs.LG}
}